
Go Getter Part 3
Oct 5, 2013 · 5 minute read · Commentsprogramming
Hurray multi-threading
This is the second follow up article to the slightly polarizing original which had solely focused on extracting the max performance out of Go. The C++ community has really stepped up the game now. A few extreme pull requests (thanks t-mat and m42a) later the C++ version is essentially running on steroids. I thought it was a good time to rerun the benchmarks and see how things fared.
Plug: The original project (https://github.com/kidoman/rays) is now restructured so that we can add in new language implementations and see how they fair in this micro-benchmark.
Go Land
Things were not quite in the Go land. I looked at the awesome optimizations contributed by m42a and ported a few things over to Go (+ a little spice of my own.) A quick run down:
Inlining Rand
The origin rand function, although elegant, was not getting inlined by the Go compiler. I would always suggest building performance sensitive parts of your application with the ‘-m’ flag, like so:
go build -gcflags -m
When I ran this on the projects main.go, it was immediately apparent that the anon-func inside makeRand() was not getting inlined as it was dependent on the ‘seed’ variable:
type randFn func() float64
func makeRand(seed uint32) randFn {
return func() float64 {
seed += seed
seed ^= 1
if int32(seed) < 0 {
seed ^= 0x88888eef
}
return float64(seed%95) / float64(95)
}
}
The solution was to simplify this and get it to inline:
func rnd(s *uint32) float64 {
ss := *s
ss += ss
ss ^= 1
if int32(ss) < 0 {
ss ^= 0x88888eef
}
*s = ss
return float64(*s%95) / float64(95)
}
The callers pass in the seed and life is good again. This simple change netted a 4.3 % improvement. Not too shabby.
Computing the bounce vector
@@ -223,11 +223,15 @@ func tracer(orig, dir vector.Vector) (st status, dist float64, bounce vector.Vec
if s < dist && s > 0.01 {
dist = s
- bounce = p.Add(dir.Scale(dist)).Normalize()
+ bounce = p // We can lazy compute bounce based on value of p
st = hit
}
}
}
+ if st == hit {
+ bounce = bounce.Add(dir.Scale(dist)).Normalize()
+ }
+
return
}
(link to diff)
This shaved off a further 4 % from the execution time. The reason: instead of doing a expensive Normalize() (line 5) call inside a loop, why not pull it out and do it only if ‘st’ == ‘hit’
Objects
@@ -27,18 +27,14 @@ var art = []string{
var objects = makeObjects()
-type object struct {
- k, j int
-}
-
-func makeObjects() []object {
+func makeObjects() []vector.Vector {
nr := len(art)
nc := len(art[0])
- objects := make([]object, 0, nr*nc)
+ objects := make([]vector.Vector, 0, nr*nc)
for k := nc - 1; k >= 0; k-- {
for j := nr - 1; j >= 0; j-- {
if art[j][nc-1-k] != ' ' {
- objects = append(objects, object{k: -k, j: -(nr - 1 - j)})
+ objects = append(objects, vector.Vector{X: -float64(k), Y: 3, Z: -float64(nr-1-j) - 4})
}
}
}
@@ -215,10 +211,8 @@ func tracer(orig, dir vector.Vector) (st status, dist float64, bounce vector.Vec
st = missDownward
}
- for _, object := range objects {
- k, j := object.k, object.j
-
- p := orig.Add(vector.Vector{X: float64(k), Y: 3, Z: float64(j - 4)})
+ for i, _ := range objects {
+ p := orig.Add(objects[i])
b := p.DotProduct(dir)
c := p.DotProduct(p) - 1
q := b*b - c
Got rid of the separate object struct and leveraged the Vector struct to get rid of some repeatitive operations inside the loop.
Some of theses changes need to be ported back to C++ (not that it needs them); but I haven’t had time yet.
Alright, alright, give me the results
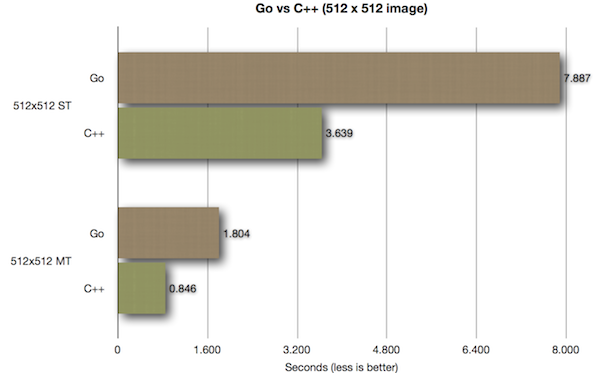
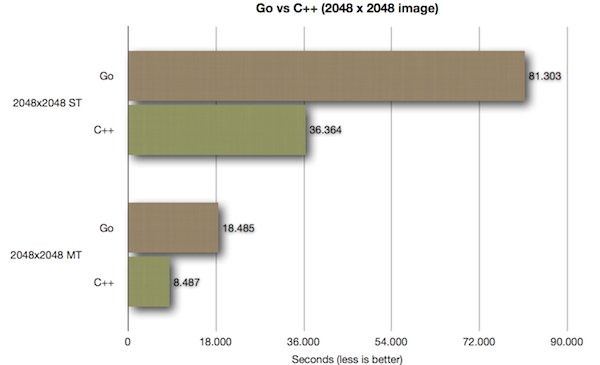
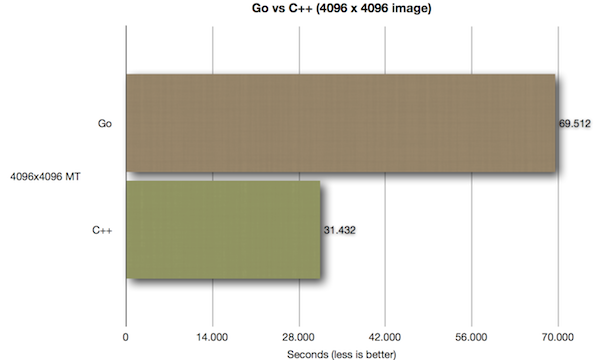
All of the above benchmarks were run on a Hetzner dedicated server machine with a i7 2600 + 16 GB RAM
At this stage, C++ is now more than twice as fast as an equivalent Go program. If you look at the previous 2048 x 2048 test results, you will see how far ahead the C++ results have come:
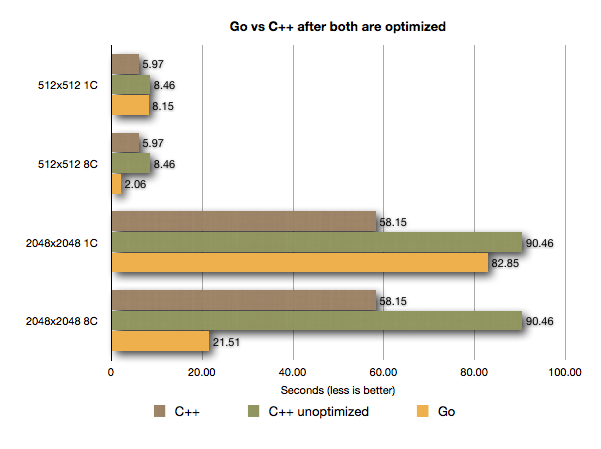
From taking 58.15 seconds (single threaded), it has now dropped to a extremely impressive 36.36 seconds (again single threaded), making it almost twice as fast as the optimized Go version.
Conclusion
I am pretty sure the Go version will get closer and closer as the compiler gets more mature. Its just a matter of time. Infact, a few common compiler optimization misses are causing it to not extract as much performance as it potentially could. But thats the subject of a different blog post (this one is already getting too long.)
Also, it will be worthwhile to test how gccgo performs with the same code.
Road Ahead
I have restuctured the github project (https://github.com/kidoman/rays) so that it is easy to add other language implementations to it. A Java, Clojure, Rust, Python, etc. version would definitely make things interesting and spice things up a bit. If you are interested in picking up a cause, please go right ahead… all pull requests are welcome.
As usual, reachable at kidoman@gmail.com / @kidoman_
Reddit Discussion Thread
Hacker News Discussion Thread
Tweet this