
Go Getter
Oct 2, 2013 · 10 minute read · Commentsprogramming

A ray traced image produced by the program
Long story short: After optimizations, the Go ray tracer was 8.4 % faster than a functionally equivalent C++ (but unoptimized*) version when rendering a 4.2 MegaPixel image using a single thread. With multi-threading enabled, the performance gap widened to 76.2 % on a 8 Core machine. Not only was it really simple to utilize the complete CPU in Go, it was easy to immediately feel productive in the language due to its simple and thoughtful design. “Less is indeed more !“
*Update: I have posted a follow up article with the benchmarks rerun using a optimized C++ solution.
*Update 2: I have posted a second follow up article with the benchmarks rerun with a multi-threaded optimized C++ version.
Ray tracing? **
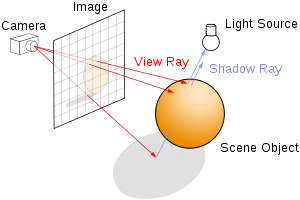
Ray tracing is a technique for generating an image by tracing the path of light through pixels in an image and simulating the effects of its encounters with virtual objects.
Since it is computationally intensive and you figure out the final color of each pixel on its own, without caring about neighbouring pixels, the algorithm is inherently parallelizable; atleast in its current form.
Although a poor fit for rendering realtime graphics (read games and simulations where speed is critical) without expensive hardware, it sees a lot of usage in the film and television where the image can be rendered slowly ahead of time.
Fire your engines
Few days ago, I chanced upon this blog post on Hacker News.
I loved the breakdown provided by the author, and frankly speaking, since the subject was about ray tracing, it didn’t take much for me to get fully engrossed in it. I mean, a ray tracer, concise enough to fit at the back of the business card, measuring up to a grand total of 1337 bytes… yummmmmmmmmmmy!
Like any programmer worth his salt, I immediately decided to port this brilliant piece of art to a programming language I am trying to internalize, Go. Did I hear you ask “Why Go ?”
- Go is poised to be fast, system level programming language
- Performance is one of the key factors
- Scaling to multiple cores is supposed to be a breeze
- Its supposedly easy to leverage all the features provided by the Go language and runtime and write “correct” and “idiomatic” programs
So a couple of hours later, I got the first version up and running. I modified both the C++ and the Go versions slightly to generate the same exact image (512 x 512) so that it was as close a comparision as possible (no disrespect to prodigal aek.)
{kind=link}
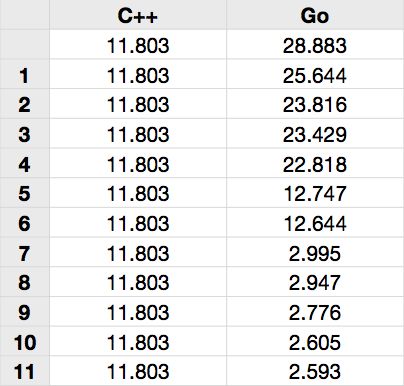
This is how the numbers stacked up:
- C++ version: 11.803 s
- Go version: 28.883 s
Not too shabby for a few hours of coding, but obviously I was not going to let it rest there. I decided to seek help from the community.
Note: All initial testing was done on a Late-2011 MacBook Pro 15 with a Intel i7 2675QM processor, equipped with 16GB of RAM, running Mac OS X 10.9
Links
- Golang-nuts discussion thread: link
- gorays Github repo: link
- C++ version gist: link
- Various parallel options tried: link
Aside
There seems to be a misconception (by and large) that there is a lack of community support around Go. But it could not be far from the truth. 2013 has been the best year for Go as far as I can tell. The first “big” conference around Go has been announced + the energy around Go in the community is at a new high. The amount of code being written in Go is also on a rise. Just have a look at the language stats page in Github to get a brief overview.
My first step was to collate all the information I had about my problem statement into a post at golang-nuts: the post
The amount of constructive advice I got in the first couple of hours was amazing. Let me summarize some of the biggest performance leaps for you:
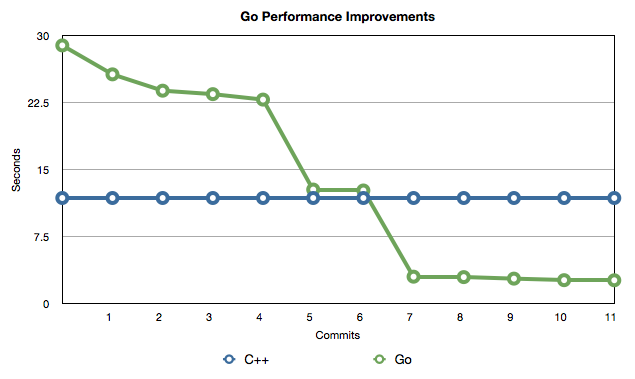
Graph of Go performance improvements
(raw data available here, also C++ solution was kept constant while optimizing the Go version)
{kind=link}
Move to go1.2rc1
Change# 1
Before: 28.883 s
After: 25.644 s
Change: 11.2 %
The initial benchmark run was on go1.1.2. But it didn’t make sense to continue benchmarking on this old/stable release as the 1.2 release is just around the corner and 1.2rc1 is already available; with performance improvements in tow.
This is one awesome property of Go. Every new release, we are magically given a new leash on life in form of additional performance without having to make a single line of change. And since we are guaranteed that a well formed Go1 code will continue to work and compile with all Go1.x releases, this is “sone pe suhaga” (for my English speaking brethren: icing on the cake.) For example, the Go1.1 release saw as much as a 30% boost in performance for a lot of Go programs over Go1.0.
In this particular case, it was a 11.2 % win. With zero changes to code. Hurray!
Global to Local Rand
Change# 2 (commit 2)
Before: 25.644 s
After: 23.816 s
Change: 7.13 %
This one was a doozy. I will mark this up to my inexperience with Go in general and lack of sleep in particular. The convenience of the in built math/rand package’s rand.Float64() caught me of guard. What Sebastien Binet rightly pointed out, and what is amply clear from the documentation, is that rand.Float64() is thread safe and is overkill in single threaded/goroutined/gophered scenario. It uses locks internally to ensure that multiple goroutines (parallel to threads in other dimensions) can access it without mucking up (in general.)
Needless to say, using a local rand (i.e. calling rand.New(…) and using the returned instance everywhere) netted me a cool 7.13 % boost.
Buffer to Win
Change# 3 & 4 (commit 3 and commit 4)
Before: 23.816 s
After: 22.818 s
Change: 4.23 %
This was a two parter (as are all good movies.) The first part involved not writing to os.Stdout inside the inner loop of the ray tracer. I guess writing to os.Stdout is not bad in general, but placing it inside a super tight inner loop (which essentially iterates through every pixel of the rendered image) is a big NO-NO! Getting rid of that was easy. Just use a bytes.Buffer (hat tip to Robert Melton.)
The real win was avoiding the allocation of a byte slice inside the inner loop. Its common knowledge in the Go world: lesser the garbage you create, the more performant your application becomes. By avoiding the allocation of the byte slice per pixel (thanks Nigel Tao), we optimized things further and brough the overall execution time down to 22.818 s (2x compared to the C++ version.) Not too shabby.
Engage Warp Engines
Change# 5 (commit 5)
Before: 22.818 s
After: 12.747 s
Change: 44.14 %
I did myself a solid by looking closely at the tracer() function. It was being called a gazillion times and required some much needed love. Instead of looping through all possible “potential” spheres every time tracer was called, why not precompute the various possible sphere locations (information which is readily available) and avoid the double loop in the first place?
This minor optimization saw the most massive jump thus far. A 44.14 % boost. And now, we were just 0.944 s shy of the C++ program’s raw speed. Was this a apples-to-apples comparison anymore? Well no, but it was never meant to be. Attempt was to use the best of what Go has to offer to extract maximum performance. And we were barrelling down that road.
Scotty, is that all you got?
Change# 6 (commit 6)
Before: 12.747 s
After: 12.644 s
Change: 0.81 %
This is a significant change (thanks to the suggestion from kortschak) but probably subdued as it came late in the game. Yep, thats right, its the damn rand function again. Apparently, it’s okay to NOT use a random generator when generating a raytraced image. The already well oiled engine quickened a little further to 12.644 s (an improvement of 0.81 %)
Warp Speed Ahead
Change# 7 & 8 (commit 7 and commit 8)
Before: 12.644 s
After: 2.947 s
Change: 76.69 %
Concurrency (not parallelism) is the forte of Go. It makes it easy to think in concurrent terms. In fact, you can end up coding a replicated search client which reduces tail latency without having to use a lock, conditional variable or callback.
However, ray tracing (at least in its currently coded form) is inherently a parallel problem. So how did Go fair? Very well, thanks for asking.
I tried a couple of approaches and this one worked the best. One reason why I could try all these approaches so quickly is because of how easy it was to express my intent in Go. And that is an understatement.
Final approach used: Fire up N* goroutines and have them on standby; with each one capable of rendering a full row of the image. Then queue up all the rows that need rendering in a channel which feeds into all the available goroutines. There is no starvation as each goroutine has work available the moment it gets done with its current row. Awesome right? No locks, conditional variables or callbacks!
*N = runtime.NumCPU()
Smart Pow
Change# 9, 10 & 11 (commit 9, commit 10 and commit 11)
Before: 2.947 s
After: 2.593 s
Change: 12.01 %
Michael Jones rightly pointed (twice) that multiplications are way better that math.Pow when the exponents are known and optimization friendly (like 4 and 99.) Having exponentiation in the language itself would definitely help as the compiler would be able to do a good job of optimizing the multiply chains.
Commit 11 also optimized things further by skipping computing r if not required (because of a potential early return.)
Base Test: Revisited
Remember this:
- C++ version: 11.803 s
- Go version: 28.883 s (single core)
Now that we have done ALL these optimizations, how do these numbers change:
- C++ version: 11.803 s
- Go version: 10.349 s (single core)
- Go version: 2.593 s (multi core)
We started the journey being 144.7 % slower than an equivalent C++ version to being 12.32 % faster, in single threaded mode. With multiple cores enabled, we ended up being 78.03 % faster than a functionally equivalent C++ version.
I also did some additional testing on a dedicated machine powered by Ubuntu 13.04 (kernel 3.8.0.26) i7 2600 with 16 GB RAM. The results were very heartwarming to say the least:
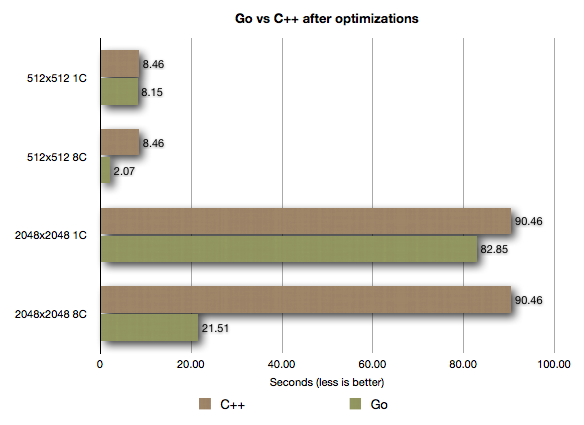
Go vs C++ after optimizations
- 1C = 1 Core
- 8C = 8 Core
Conclusion
- This much improvement would not have been possible without support from the Go community. You guys rock!
- Asking a genuine constructive question on golang-nuts has always gotten people a +ve response. Even if it is a “Sorry, it would be a difficult to do this in Go right now”
- Go is maturing quickly. Every new version brings in new backward compatible performance; just recompile your code and voila!
- It was a breeze to do the various optimizations suggested by the community, and it is very possible that some of these optimizations would not be required in the near future (like say with a language build in exponentiation)
- We are comparing C++ to a language which not only has garbage collection built into the statically compiled binary, it also has the ability to handle multiple cores / synchrony baked right into the language
- I am looking forward to redoing these tests with an optimized C++ version (single-core, multi-core) if someone is willing to contribute those changes
The succinctness and simplicity of the resultant Go code is a big BIG win! Because it is so easy to grasp all of the Go language, you are able to channelize your thought process to actually solving the problem at hand. At a much faster pace. And the best part is: more often than not, the first solution which you will code up in Go will probably be the correct solution (or very close to it.) This would definitely not have been possible if the language was any less thoughtfully designed.
Links
- Golang-nuts discussion thread: link
- gorays Github repo: link
- C++ version gist: link
- Various parallel options tried: link
That’s all folks. Thanks for reading. If you have any comments, feel free to leave them here on the blog or you can always email me at kidoman@gmail.com. Also reachable at @kidoman_ on Twitter. Ciao!
Reddit Discussion Thread
Hacker News Discussion Thread
Tweet this